os momentos populacionais aos momentos amostrais. O primeiro momento momento amostral é dado pela própria média amostral, isto é,
$$
m_1=\sum_{i=1}^{n} \frac{X_i}{n}
$$
De maneira geral, para $k=1, 2, \dots$, temos o $k$-ésimo momento amostral:
$$
m_k=\sum_{i=1}^{n} \frac{X_i^k}{n}
$$
Assim, o sistema é obtido ao fazermos:
$$
m_k=E(X^k)
$$
e resolvendo para encontrar as estimativas dos parâmetros da distribuição desejada.
Exemplo:
Para a distribuição Uniforme(a,b), temos dois parâmetros: $a$ e $b$. Serão necessárias duas equações para encontrarmos $\tilde{a}$ e $\tilde{b}$, os estimadores obtidos por meio do método dos momentos. As equações que utilizaremos são:
$$
m_1=E(X) \Rightarrow \sum_{i=1}^{n} \frac{X_i}{n} = \frac{\tilde{a}+\tilde{b}}{2}
$$
$$
m_2=E(X^2) \Rightarrow \sum_{i=1}^{n} \frac{X_i^2}{n} = \frac{\tilde{a}^2+\tilde{a}\tilde{b}+\tilde{b}^2}{3}
$$
Resolvendo a equação $m_1=E(X)$, obtemos $\tilde{a}=2 \bar{X} - \tilde{b}$, em que $\bar{X}$ é a média amostral.
Com a segunda equação, $m_2=E(X^2)$, obtemos $\tilde{b}=\bar{X} + \sqrt{3(m_2-\bar{X}^2)}$.
Assim, temos que os estimadores pelo método dos momentos para a distribuição Uniforme(a,b) são dados por:
$$
\tilde{a}=2 \bar{X} - \tilde{b}= \bar{X} - \sqrt{3(m_2-\bar{X}^2)}
$$
$$
\tilde{b}=\bar{X} + \sqrt{3(m_2-\bar{X}^2)}
$$
O gráfico a seguir mostra o resultado para uma amostra proveniente de uma distribuição Uniforme(5,9), de tamanho $n=1000$. Nas linhas vermelhas estão os valores verdadeiros dos parâmetros ($a=5$ e $b=9$) e nas linhas verdes estão as estimativas obtidas pelos estimadores discutidos nesta postagem ($\tilde{a}=4,97$ e $b=8,90$).
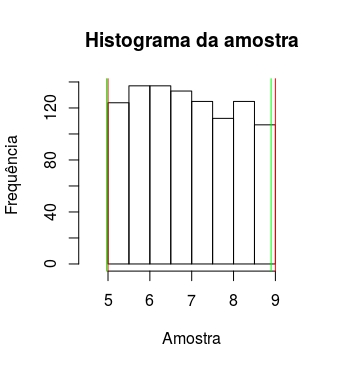
Uma reflexão importante sobre a distribuição uniforme é que seu estimador obtido pelo método dos momentos não é função de estatística suficiente.
Por exemplo, no caso da distribuição Uniforme($0, \theta$) o estimador obtido pelo método dos momentos é igual a $\tilde{\theta}=2\bar{X}$, que não é função da estatística suficiente desta distribuição, que é o máximo, $X_{(n)}$.
Questão de Concurso:
Perceba como essa reflexão foi cobrada no último concurso do Supremo Tribunal Militar (STM), na prova para o cargo de Estatístico, elaborada pela banca CESPE, em 2011:
Item: "Qualquer estimador obtido pelo método dos momentos é uma função de estatística suficiente."
Resposta: O exemplo acima mostra um contraexemplo. Item errado.




